

Selective, Interpretable, and Motion Consistent Privacy Attribute Obfuscation for Action Recognition2024 Conference on Computer Vision and Pattern Recognition |
The goal is to hide privacy relevant attributes without action recognition performance dropping. We show that it is not necessary to train action recognition and privacy networks in an adversarial fashion for effective obfuscation of privacy attributes while maintaining strong action recognition performance. We show that a system based on local privacy templates, deep features that capture template semantics and selective noise obfuscation that is animated with source video motion can uphold privacy without hindering action recognition. Our approach is unique compared to alternative recent approaches in terms of interpretability.
Overview
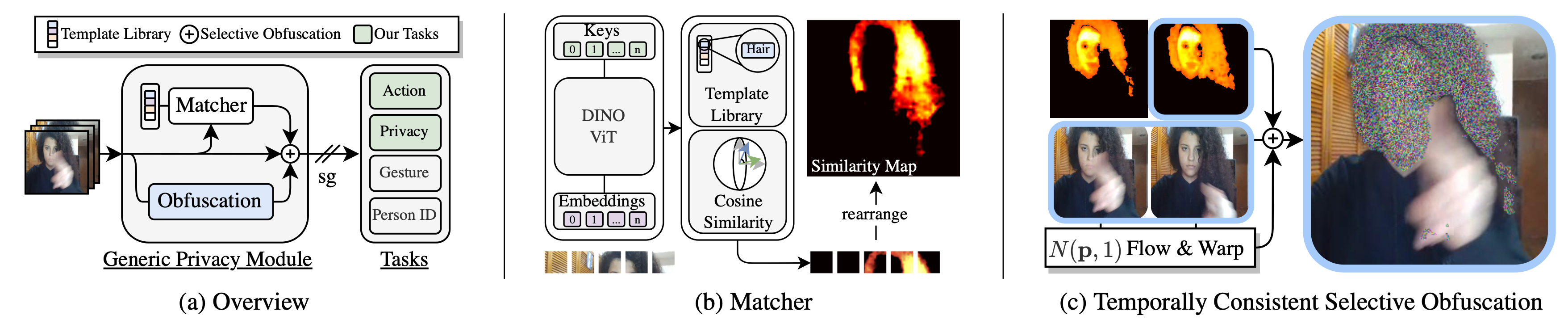
Our method uses templates that we match with DINO-ViT features to find salient regions in video that we need to obfuscate. We create a template library of images, and spatial locations in these images \({\tau}_i \in \mathsf{T}\), which correspond to regions that ought to be obfuscated. In our particular usecase this means regions that can be used to infer labels pertaining to privacy (Skintone, Haircolor, Gender, …).

We use the keys of a DINO-ViT as the feature descriptors, as they accumulate contextual and semantic meaning, as depth increases in the Vision Transformer.
Saliency Computation
To decide how strong a particular patch needs to be obfuscated we use the (positive) cosine similarity between the templates and the image patches.
\[s_j = \frac{1}{|\tilde{\mathsf{T}}|} \sum_{i=1}^{|\tilde{\mathsf{T}}|} \max\left(0, \frac{ \langle \mathsf{K}(\tau_i), \mathsf{K}(I_j)\rangle}{\|\mathsf{K}(\tau_i)\|\|\mathsf{K}(I_j)\|}\right), \forall j \in \{1,..., m\}\]The resulting saliency map is then bilinearly upscaled, to be of the same dimension as the input image. This process ensures that only targeted areas are obscured, thus preserving the, often critical, context for action recognition.
These maps highlight the regions that match our privacy-sensitive attributes, effectively pinpointing where obfuscation is needed.
Temporally Consistent Masking
Once we’ve identified these regions, we overlay temporally consistent noise on the input video, guided by the saliency maps.The key here is to maintain the integrity of the video’s motion and overall context, crucial for action recognition, while effectively masking personal attributes.
Examples of such temporally consistent noise are found on the project page of our previous work. Below we show examples of input video, motion consistent noise, the saliency maps, and the final masked output that is used in the action recognition networks.




Results
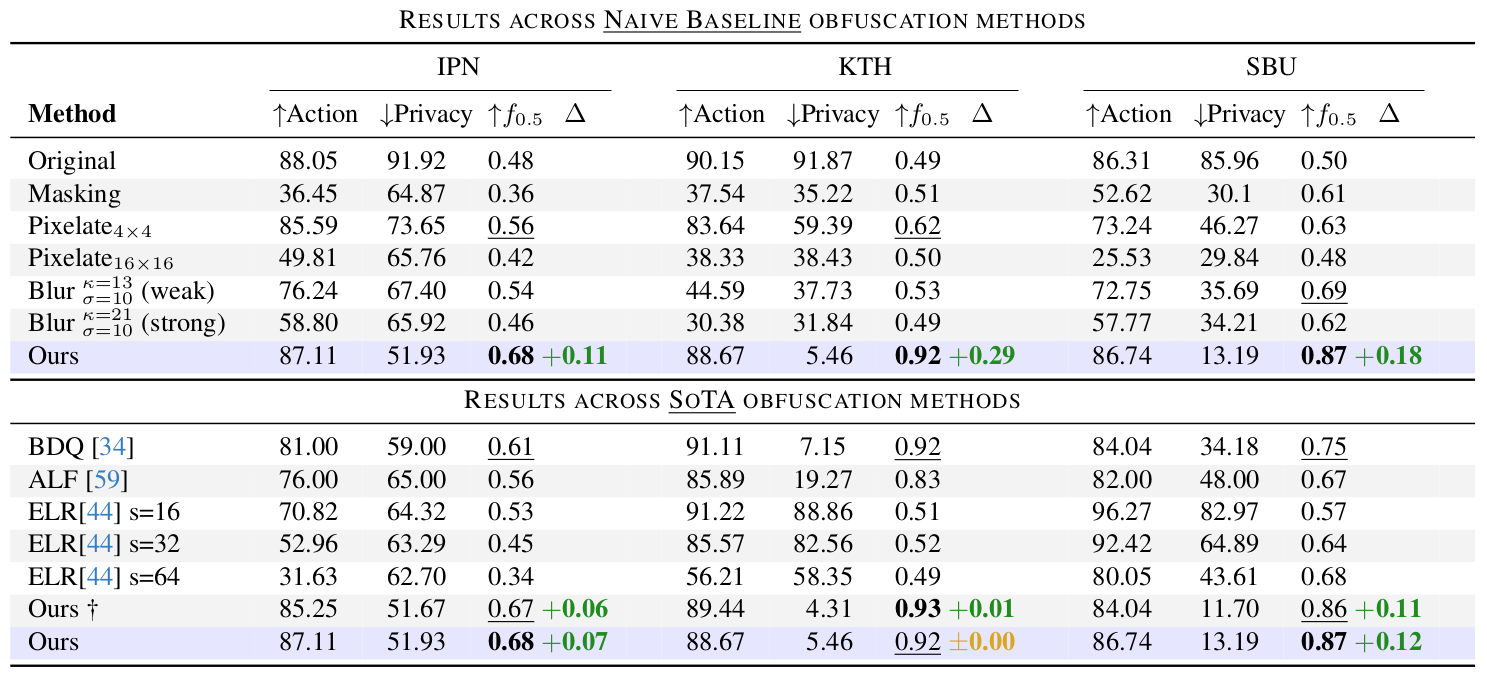
We compare across 11 Action Reocgnition, and 6 Privacy Attribute Classification architectures; We show across all three tested datasets (IPN, SBU, KTH) that our relatively simple approach of finding similarities and masking it with temporally consistent noise works quite well and outperforms other approaches that require training for each specific architecutre.
Cite
@inproceedings{ilic2024selective,
title={Selective, Interpretable and Motion Consistent Privacy Attribute Obfuscation for Action Recognition},
author={Ilic, Filip and Zhao, He and Pock, Thomas and Wildes, Richard P.},
booktitle={Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2024}
}
Further Reading
|
ECCV
|
Is Appearance Free Action Recognition Possible?
2022 European Conference on Computer Vision
|
|
WACV
|
Representing Objects in Video as Space-Time Volumes by Combining Top-Down and Bottom-Up Processes
2020 Winter Conference on Applications of Computer Vision
|