

Is Appearance Free Action Recognition Possible?2022 European Conference on Computer Vision |




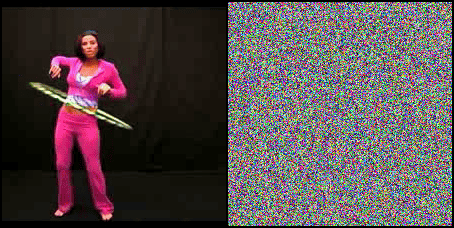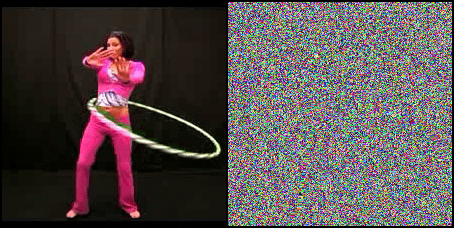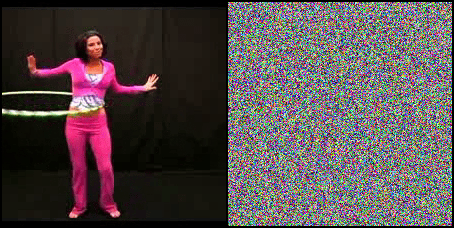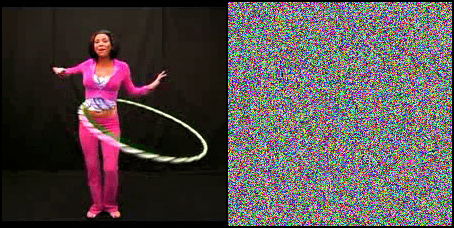
Can Neural Networks recognize actions solely from the temporal dynamics?
We investigate state-of-the-art action recognition networks with respect to their performance on a dataset where no static information is present. The video shows random noise animated with motion extracted from real human motion (the UCF101 dataset). We find that optical flow, or a similarly descriptive representation, is not an emergent property of any of the tested action recognition architectures.
Motivation
Related work has shown often that static biases in action recognition datasets and therefore also in the trained models exist.
A simple experiment demonstrates that singleframe classification performance of a ResNet50 on UCF101 frames yields 65.6% Top-1 accuracy.

The Appearance Free Dataset (AFD) disentangles static and dynamic video components. In particular, no single frame contains any static discriminatory information in AFD; the action is only encoded in the temporal dimension.
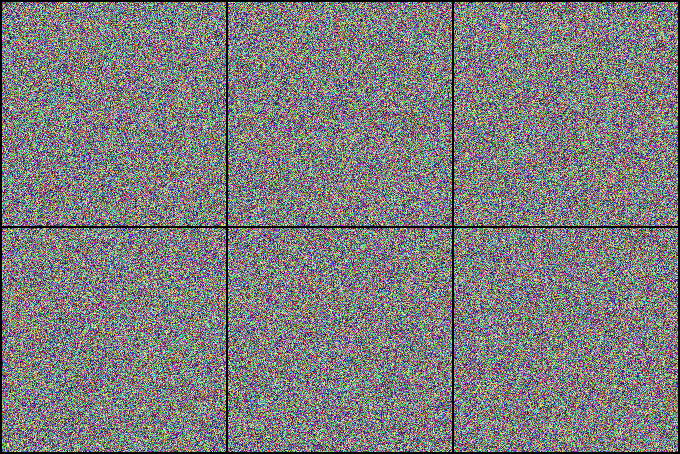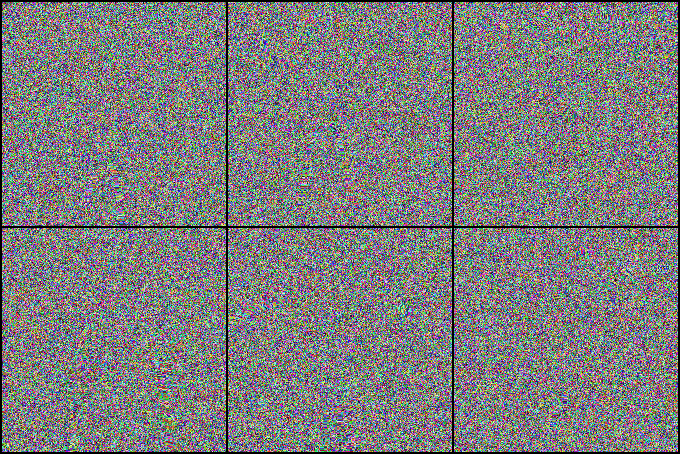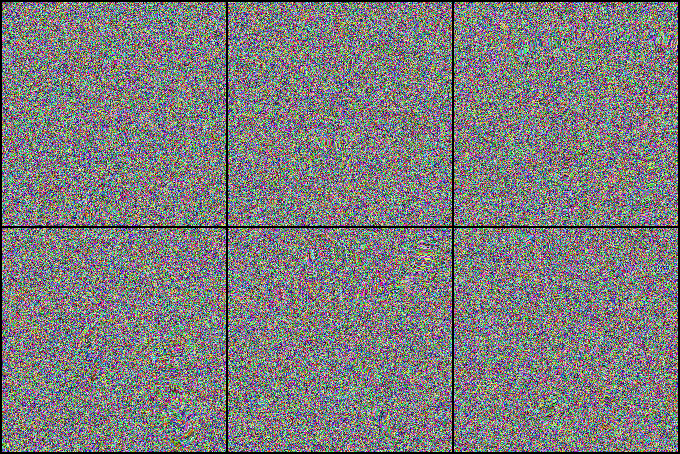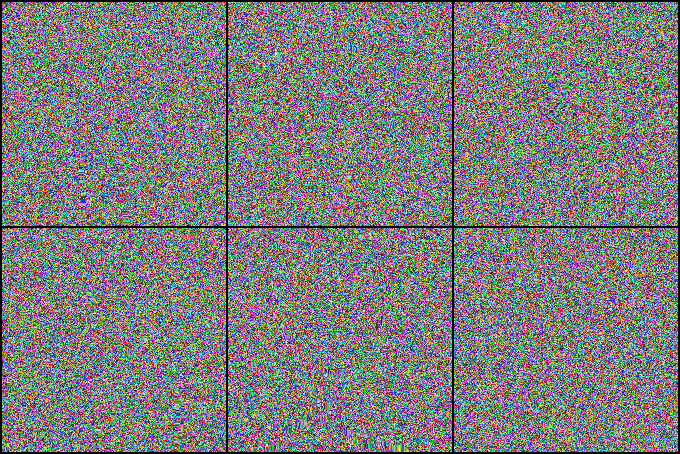


Psychophysical Study
AFD101 is based on UCF101. We provide code and other necessary tools to generate other appearance free videos.
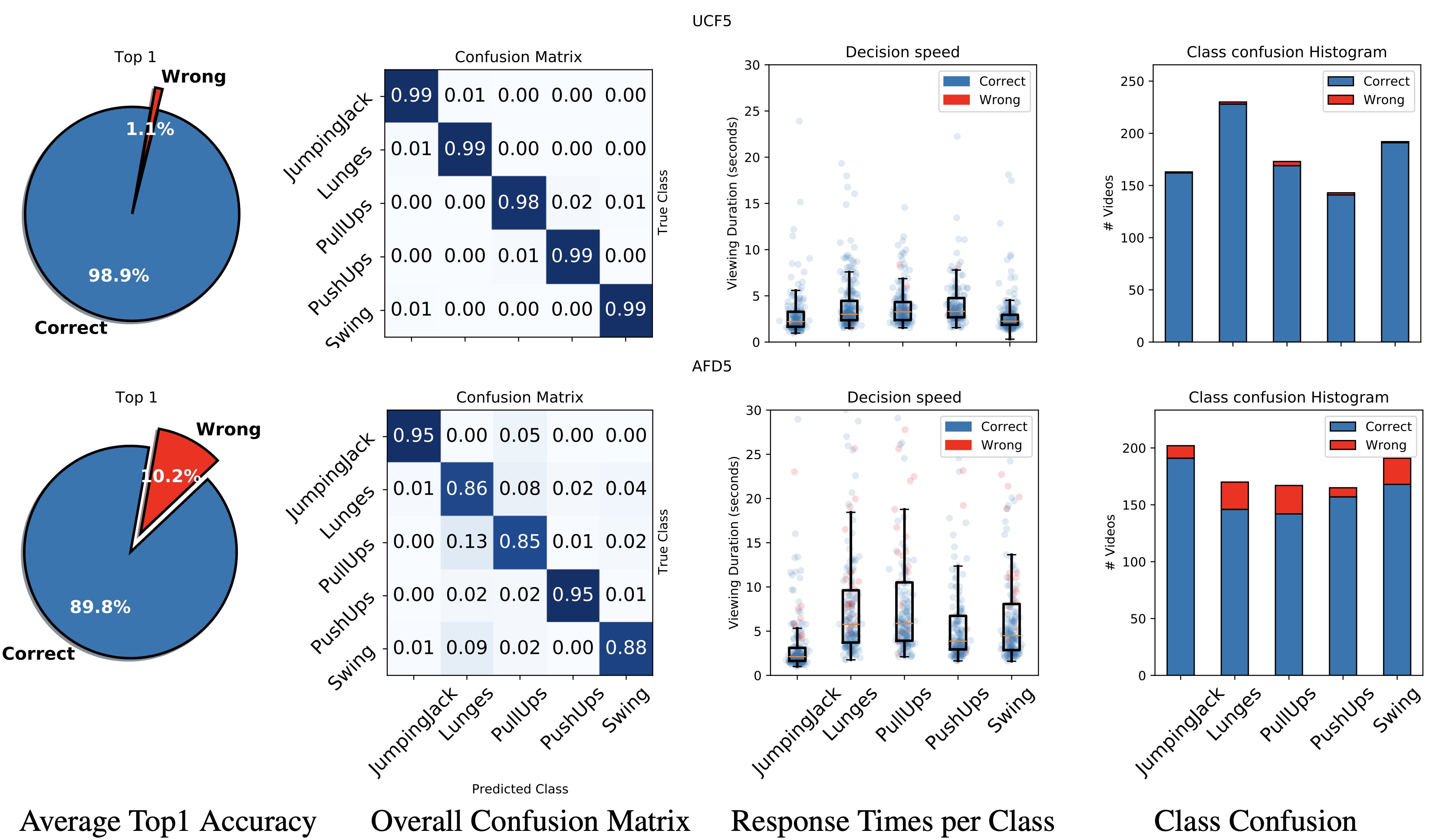
We also perform a user study, showing that human participants can detect the motion from the animated noise patter, and perform much better than current networks. The top row shows human performance on “normal” videos, and the bottom row on our “noisy” videos.
Our Userstudy shows that people can identify actions from anmiated noise.
It’s also possible to start with different noise (e.g. sparse) and still descern moving shapes.
 |
 |
 |
Using sparse noise, we can create videos that evoke a familiarity, at least in spirit, to the perceptual organization experiments of simple movements performed by psychologist Gunnar Johansson [Ref].
Video modified from: [Credit]
Proposed Architecture
One of our contributions is to show how to build a (new) Two-Stream architecture in a pricipled manner, to encourage a robust modeling of the temporal dimension.
We call it Explicit-Two-Stream, as one stream explicitly models temporal correlations through the use of RAFT blocks.
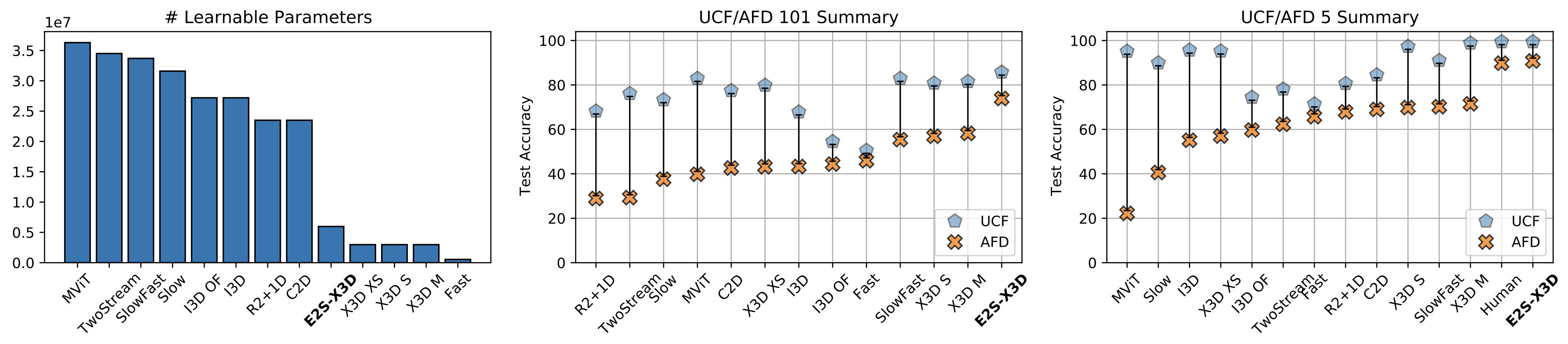
This design choice for our network allows for a rich dynamics representation that outperforms other methods on Appearance Free Data. We show that it closes the gap to human performance on Appearance Free Data significantly.
Cite
@InProceedings{ilic22appearancefree,
title={Is Appearance Free Action Recognition Possible?},
author={Ilic, Filip and Pock, Thomas and Wildes, Richard P.},
booktitle={European Conference on Computer Vision (ECCV)},
month={October},
year={2022},
}
Further Reading
|
CVPR
|
Selective, Interpretable, and Motion Consistent Privacy Attribute Obfuscation for Action Recognition
2024 Conference on Computer Vision and Pattern Recognition
|
|
Physicalization
|